문제 설명
블록게임
프렌즈 블록이라는 신규 게임이 출시되었고, 어마어마한 상금이 걸린 이벤트 대회가 개최 되었다.
이 대회는 사람을 대신해서 플레이할 프로그램으로 참가해도 된다는 규정이 있어서, 게임 실력이 형편없는 프로도는 프로그램을 만들어서 참가하기로 결심하고 개발을 시작하였다.
프로도가 우승할 수 있도록 도와서 빠르고 정확한 프로그램을 작성해 보자.
게임규칙
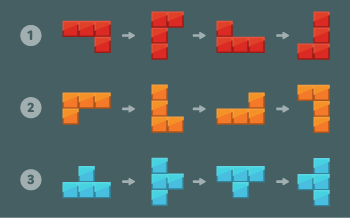
아래 그림과 같이 1×1 크기의 블록을 이어 붙여 만든 3 종류의 블록을 회전해서 총 12가지 모양의 블록을 만들 수 있다.
1 x 1 크기의 정사각형으로 이루어진 N x N 크기의 보드 위에 이 블록들이 배치된 채로 게임이 시작된다. (보드 위에 놓인 블록은 회전할 수 없다). 모든 블록은 블록을 구성하는 사각형들이 정확히 보드 위의 사각형에 맞도록 놓여있으며, 선 위에 걸치거나 보드를 벗어나게 놓여있는 경우는 없다.
플레이어는 위쪽에서 1 x 1 크기의 검은 블록을 떨어뜨려 쌓을 수 있다. 검은 블록은 항상 맵의 한 칸에 꽉 차게 떨어뜨려야 하며, 줄에 걸치면 안된다.
이때, 검은 블록과 기존에 놓인 블록을 합해 속이 꽉 채워진 직사각형을 만들 수 있다면 그 블록을 없앨 수 있다.
예를 들어 검은 블록을 떨어뜨려 아래와 같이 만들 경우 주황색 블록을 없앨 수 있다.

빨간 블록을 가로막던 주황색 블록이 없어졌으므로 다음과 같이 빨간 블록도 없앨 수 있다.

그러나 다른 블록들은 검은 블록을 떨어뜨려 직사각형으로 만들 수 없기 때문에 없앨 수 없다.
따라서 위 예시에서 없앨 수 있는 블록은 최대 2개이다.
보드 위에 놓인 블록의 상태가 담긴 2차원 배열 board가 주어질 때, 검은 블록을 떨어뜨려 없앨 수 있는 블록 개수의 최댓값을 구하라.
제한사항
- board는 블록의 상태가 들어있는 N x N 크기 2차원 배열이다.
- N은 4 이상 50 이하다.
- board의 각 행의 원소는 0 이상 200 이하의 자연수이다.
- 0 은 빈 칸을 나타낸다.
- board에 놓여있는 각 블록은 숫자를 이용해 표현한다.
- 잘못된 블록 모양이 주어지는 경우는 없다.
- 모양에 관계 없이 서로 다른 블록은 서로 다른 숫자로 표현된다.
- 예를 들어 문제에 주어진 예시의 경우 다음과 같이 주어진다.

접근 방법
특별하게 사용할 알고리즘이 따로 생각나지 않는 시뮬레이션 문제였습니다.
접근 방법은 아래와 같습니다.
1. board의 전체에 1개씩 검은 블록을 떨어트린다.
2. 제거 할 수 있는 블록이 있는지 확인한다. 제거할 수 있는 블록이 있다면 제거한다.
3. 2에서 블록이 제거 되었다면 board에 남아있는 모든 검은 블록을 제거한다. 어떤 블록도 제거되지 않았다면 놔둔다.
4. 1번부터 반복 (만약 3번 연속 블록이 제거되지 않았다면 더 이상 제거할 블록이 없다는 것이므로 반복을 종료한다.)
int solve(vector<vector<int>> &board){
int total = 0;
int zeroCnt = 0;
while(zeroCnt < 3){
stackBlack(board); //1번: 검은 블록을 전체에 떨어트림
int cnt = check(board); //2번: 제거 할 수 있는 블록을 count
//3번
if(cnt == 0)
zeroCnt++;
else{
eraseBlack(board);
zeroCnt = 0;
}
total += cnt;
}
return total;
}
1. board의 전체에 1개씩 검은 블록을 떨어트린다.
한 열의 가장 위 부터 확인하며 어떤 블록이 발견되면 검은 블록을 쌓습니다. 저와 같은 경우 검은 블록은 -1로 표기 하였습니다. 이 때 주의할 점은 블록이 board의 최상단까지 쌓여있다면 다음 열로 넘어가야 한다는 것입니다.
void stackBlack(vector<vector<int>> &board){
for(int i=0;i<board.size();i++){ //i가 가로
for(int j=0;j<board[i].size();j++){ //j가 높이
if(board[j][i] != 0){
if(j == 0) //보드의 가장 위에 블록이 있다면
break;
board[j - 1][i] = -1;
break;
}
}
}
}
2. 제거 할 수 있는 블록이 있는지 확인한다. 제거할 수 있는 블록이 있다면 제거한다.
일단 board의 처음부터 끝까지 한 칸씩 스캔을 하다 어떤 블록이 발견되면 그 위치에서 제거할 수 있는 블록이 있는지 확인을 합니다. 이 때 제거할 수 있는 블록의 형태는 3x2또는 2x3이므로 두 가지 형태에 대해 검사를 합니다.
int check(vector<vector<int>> &board){
int cnt = 0;
for(int i=0;i<board.size();i++)
for(int j=0;j<board.size();j++)
if(board[i][j] != 0)
if(checkOneArea(i,j,2,3,board) || checkOneArea(i,j,3,2,board)) // 2*3모양 3*2모양에 대해서만 확인하면 됨
cnt++;
return cnt;
}
checkOneArea()함수에서는 매개변수로 확인해야할 지점과 범위를 매개변수로 주어 제거할 수 있는 블록이 있다면 제거를 한뒤 true를 반환하고, 제거할 수 있는 블록이 없다면 false를 반환합니다.
이 때 제거할 수 있는 블록의 조건으로는 모든 기본 블록은 4개로 이루어져 있기 때문에 검은블록(-1)이 무조건 2개만 포함이 되어야 한다는 것이고 검은 블록과 제거할 블록의 색 외에 다른 어떠한 색도 포함이 되면 안된다는 것입니다.
bool checkOneArea(int x, int y, int x_len, int y_len, vector<vector<int>> &board){
int color = 0;
int blackCnt = 0;
//검사 범위를 벗어나는 경우
if(board.size() < x + x_len || board.size() < y + y_len)
return false;
for(int i = x; i < x + x_len; i++){
for(int j = y; j < y + y_len; j++){
if(board[i][j] == 0)
return false;
if(board[i][j] == -1)
blackCnt++;
if(board[i][j] != -1 && color == 0) //검은 블록이 아닌 블록의 색을 color에 지정
color = board[i][j];
if(board[i][j] != -1 && board[i][j] != color) //지정된 color와 다른 색이라면 제거 불가능
return false;
}
}
if(blackCnt != 2)
return false;
//블록 제거
for(int i = x; i < x + x_len; i++)
for(int j = y; j < y + y_len; j++)
board[i][j] = 0;
return true;
}
3번과 4번의 과정은 간단하므로 자세한 설명은 생략하겠습니다.
소스 코드
#include <string>
#include <vector>
using namespace std;
void stackBlack(vector<vector<int>> &board){
for(int i=0;i<board.size();i++){ //i가 가로
for(int j=0;j<board[i].size();j++){ //j가 높이
if(board[j][i] != 0){
if(j == 0)
break;
board[j - 1][i] = -1;
break;
}
}
}
}
bool checkOneArea(int x, int y, int x_len, int y_len, vector<vector<int>> &board){
int color = 0;
int blackCnt = 0;
//검사범위를 벗어나는 경우
if(board.size() < x + x_len || board.size() < y + y_len)
return false;
for(int i = x; i < x + x_len; i++){
for(int j = y; j < y + y_len; j++){
if(board[i][j] == 0)
return false;
if(board[i][j] == -1)
blackCnt++;
if(board[i][j] != -1 && color == 0) //검은 블록이 아닌 블록의 색을 color에 지정
color = board[i][j];
if(board[i][j] != -1 && board[i][j] != color) //지정된 color와 다른 색이라면 제거 불가능
return false;
}
}
if(blackCnt != 2)
return false;
//블록 제거
for(int i = x; i < x + x_len; i++)
for(int j = y; j < y + y_len; j++)
board[i][j] = 0;
return true;
}
int check(vector<vector<int>> &board){
int cnt = 0;
for(int i=0;i<board.size();i++)
for(int j=0;j<board.size();j++)
if(board[i][j] != 0)
if(checkOneArea(i,j,2,3,board) || checkOneArea(i,j,3,2,board)) // 2*3모양 3*2모양에 대해서만 확인하면 됨
cnt++;
return cnt;
}
void eraseBlack(vector<vector<int>> &board){
for(int i=0;i<board.size();i++)
for(int j=0;j<board.size();j++)
if(board[i][j] == -1)
board[i][j] = 0;
}
int solve(vector<vector<int>> &board){
int total = 0;
int zeroCnt = 0;
while(zeroCnt < 3){
stackBlack(board); //검은 블록을 전체에 떨어트림
int cnt = check(board); //제거 할 수 있는 블록을 count
if(cnt == 0)
zeroCnt++;
else{
eraseBlack(board);
zeroCnt = 0;
}
total += cnt;
}
return total;
}
int solution(vector<vector<int>> board) {
int answer = solve(board);
return answer;
}'알고리즘 > 프로그래머스' 카테고리의 다른 글
| [C++] 2017 카카오코드 예선 보행자 천국 (0) | 2021.03.18 |
|---|---|
| [C++] Summer/winter coding(2019) 지형 이동 (0) | 2021.03.16 |
| [C++] 2019 카카오 블라인드 매칭 점수 (0) | 2021.02.16 |
| [C++] 2019 카카오 블라인드 길 찾기 게임 (0) | 2021.02.16 |
| [C++] 2020 카카오 블라인드 블록이동하기 (0) | 2021.02.14 |